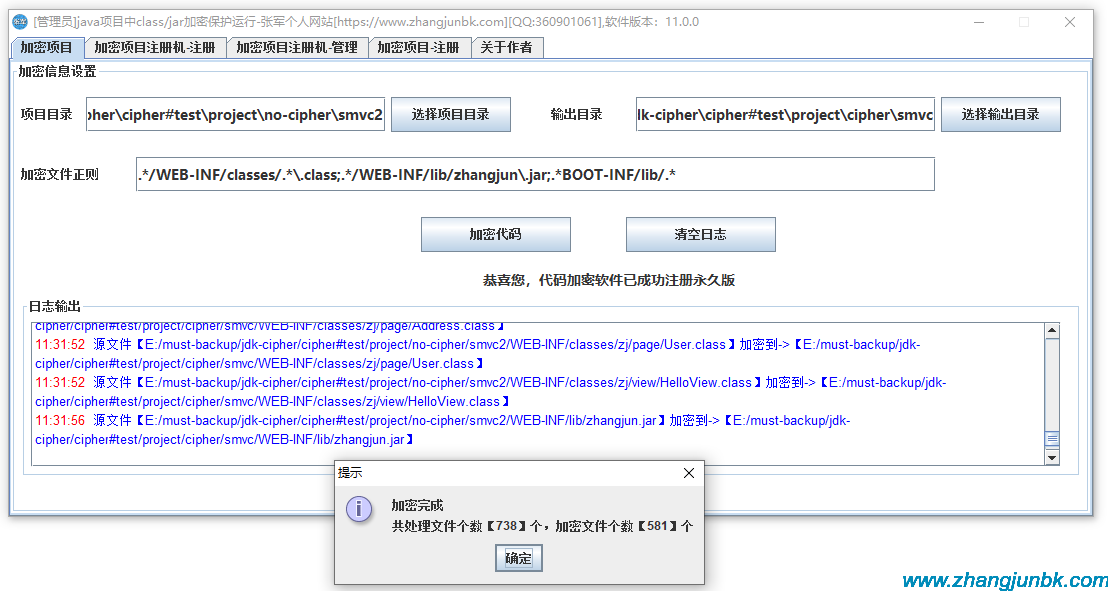
在eclipse中配置hadoop插件1.安裝插件準備程序:eclipse-3.3.2(這個版本的插件只能用這個版本的eclipse)hadoop-0.20.2-eclipse-plugin.jar(在hadoop-0.20.2/contrib/eclipse-plugin目錄下)將hadoop-0.20.2-eclipse-plugin.jar復制到eclipse/plugins目錄下,重啟eclipse。2.打開MapReduce視圖Window->O
系統(tǒng) 2019-08-29 23:25:34 3580
BloomFilter概述:目的是檢索元素是否在某個集合中,基于hash,速度比較快,不需要存儲所有的元素,只需要按照某種方式存儲hash值即可,因此比較節(jié)約內存,因此可以常駐內存加快查找速度。同時利用多個hash來解決hash沖突問題我們假定集合元素為一個列表,我們可以用一個bit列表來存儲此元素是否存在,如下所示:存在為1不存在為0,不過由于hash很容易沖突,那么可以基于多hash函數(shù)進行沖突的避免,每次設置對于的hash值為1,如下所示:也就是說x
系統(tǒng) 2019-08-12 09:29:45 3402
環(huán)境如下(停止所有服務stop-all.sh):master:master192.168.1.106slave:slave1192.168.1.107slave2192.168.1.1081、修改master(改為slave其中的一個)slave12、修改core-site.xmlfs.default.namehdfs://master:90003、修改hdf
系統(tǒng) 2019-08-12 09:29:34 3383
對namenode啟動時的相關操作及相關類有一個大體了解,后續(xù)深入研究時,再對本文進行補充>實現(xiàn)類HDFS啟動腳本為$HADOOP_HOME/sbin/start-dfs.sh,查看start-dfs.sh可以看出,namenode是通過bin/hdfs命令來啟動$vistart-dfs.sh#namenodesNAMENODES=$($HADOOP_PREFIX/bin/hdfsgetconf-namenodes)echo"Startingnamenod
系統(tǒng) 2019-08-12 09:27:18 3214
轉自:http://www.tech126.com/hadoop-lzo/自從Hadoop集群搭建以來,我們一直使用的是Gzip進行壓縮當時,我對gzip壓縮過的文件和原始的log文件分別跑MapReduce測試,最終執(zhí)行速度基本差不多而且Hadoop原生支持Gzip解壓,所以,當時就直接采用了Gzip壓縮的方式關于Lzo壓縮,twitter有一篇文章,介紹的比較詳細,見這里:Lzo壓縮相比Gzip壓縮,有如下特點:壓縮解壓的速度很快Lzo壓縮是基于Blo
系統(tǒng) 2019-08-12 09:29:35 3204
Hadoop簡介:一個分布式系統(tǒng)基礎架構,由Apache基金會開發(fā)。用戶可以在不了解分布式底層細節(jié)的情況下,開發(fā)分布式程序。充分利用集群的威力高速運算和存儲。Hadoop實現(xiàn)了一個分布式文件系統(tǒng)(HadoopDistributedFileSystem),簡稱HDFS。HDFS有著高容錯性的特點,并且設計用來部署在低廉的(low-cost)硬件上。而且它提供高傳輸率(highthroughput)來訪問應用程序的數(shù)據,適合那些有著超大數(shù)據集(largedat
系統(tǒng) 2019-08-12 09:27:11 3184
系統(tǒng):CentOs664位環(huán)境:1臺namenode2臺datanode用戶名全是girdmaster192.168.1.103slave1192.168.1.104slave2192.168.1.107具體的安裝步驟如下:1、下載jdk1.6以及hadoop1.2.1(去官網下載即可,都是64位)2、使用filezilla將jdk和hadoop上傳至master服務器,jdk上傳至slave1服務器和slave2服務器3、設置host,命令如下:vi/e
系統(tǒng) 2019-08-12 09:29:34 3151
jpshadoopnamenode-formatdfsdirectory:/home/hadoop/dfs--data--current/VERSION#WedJul3020:41:03CST2014storageID=DS-ab96ad90-7352-4cd5-a0de-7308c8a358ffclusterID=CID-aa2d4761-974b-4451-8858-bbbcf82e1fd4cTime=0datanodeUuid=a3356a09-78
系統(tǒng) 2019-08-12 09:27:32 3133
openstack和hadoop的區(qū)別是什么?(一)openstack仿照的Amazon的云,hadoop仿照的是Google的云openstack注重的是虛擬化/虛擬機及其配套的服務,hadoop注重的是海量的數(shù)據分析和處理。(二)2OpenStack主要目的是做一整套的云計算基礎構架。包括云計算(Compute),網絡(Network),對象存貯(ObjectStore),鏡像文件存儲(Image),身份認證(Authentication),Block
系統(tǒng) 2019-08-12 09:27:35 3115
1.介紹本文介紹的Hadoop權限管理包括以下幾個模塊:(1)用戶分組管理。用于按組為單位組織管理,某個用戶只能向固定分組中提交作業(yè),只能使用固定分組中配置的資源;同時可以限制每個用戶提交的作業(yè)數(shù),使用的資源量等(2)作業(yè)管理。包括作業(yè)提交權限控制,作業(yè)運行狀態(tài)查看權限控制等。如:可限定可提交作業(yè)的用戶;可限定可查看作業(yè)運行狀態(tài)的用戶;可限定普通用戶只能修改自己作業(yè)的優(yōu)先級,kill自己的作業(yè);高級用戶可以控制所有作業(yè)等。想要支持權限管理需使用FairSc
系統(tǒng) 2019-08-29 21:58:39 3114
更快、更強——解析Hadoop新一代MapReduce框架Yarn摘要:本文介紹了Hadoop自0.23.0版本后新的MapReduce框架(Yarn)原理、優(yōu)勢、運作機制和配置方法等;著重介紹新的Yarn框架相對于原框架的差異及改進。編者按:對于業(yè)界的大數(shù)據存儲及分布式處理系統(tǒng)來說,Hadoop是耳熟能詳?shù)淖吭介_源分布式文件存儲及處理框架,對于Hadoop框架的介紹在此不再累述,隨著需求的發(fā)展,Yarn框架浮出水面,@依然光榮復興的博客給我們做了很詳細的
系統(tǒng) 2019-08-29 22:57:31 3093
轉載http://xuyuanshuaaa.iteye.com/blog/10633031.SSH無密碼驗證配置Hadoop需要使用SSH協(xié)議,namenode將使用SSH協(xié)議啟動namenode和datanode進程,偽分布式模式數(shù)據節(jié)點和名稱節(jié)點均是本身,必須配置SSHlocalhost無密碼驗證。執(zhí)行ssh-keygen-trsa通過以上命令將在/root/.ssh/目錄下生成id_rsa私鑰和id_rsa.pub公鑰。進入/root/.ssh目錄在
系統(tǒng) 2019-08-29 22:08:33 3084
如題:出現(xiàn)下圖中的情況(設置reduceNum=5)感覺很奇怪,排除了很久,終于發(fā)現(xiàn)是一個第二次犯的錯誤:丟了這句this.mOutputs.close();加上這句,一切恢復正常!HadoopMultipleOutputs結果輸出到多個文件夾出現(xiàn)數(shù)據不全,部分文件為空
系統(tǒng) 2019-08-12 01:32:49 3082
問題描述:在集群模式下更改節(jié)點后,啟動集群發(fā)現(xiàn)datanode一直啟動不起來。我集群配置:有5個節(jié)點,分別為masterslave1-5。在master以hadoop用戶執(zhí)行:start-all.shjps查看master節(jié)點啟動情況:NameNodeJobTrackerSecondaryNameNode均已經正常啟動,利用master:50070,LiveNodes為0,隨進入slave1:sshslave1,輸入命令jps,發(fā)現(xiàn)只有TaskTracke
系統(tǒng) 2019-08-12 01:31:42 3077
分布式計算開源框架Hadoop入門實踐(三)Hadoop基本流程一個圖片太大了,只好分割成為兩部分。根據流程圖來說一下具體一個任務執(zhí)行的情況。在分布式環(huán)境中客戶端創(chuàng)建任務并提交。InputFormat做Map前的預處理,主要負責以下工作:驗證輸入的格式是否符合JobConfig的輸入定義,這個在實現(xiàn)Map和構建Conf的時候就會知道,不定義可以是Writable的任意子類。將input的文件切分為邏輯上的輸入InputSplit,其實這就是在上面提到的在分
系統(tǒng) 2019-08-29 22:08:15 3048